
Contente

Fonte: Kran77 / Dreamstime.com
Leve embora:
Modelos de aprendizado profundo estão ensinando os computadores a pensar por conta própria, com alguns resultados muito divertidos e interessantes.
O aprendizado profundo está sendo aplicado a cada vez mais domínios e indústrias. Desde carros sem motorista, passando o Go, até a geração de imagens musicais, há novos modelos de aprendizado profundo sendo lançados todos os dias. Aqui abordamos vários modelos populares de aprendizado profundo. Cientistas e desenvolvedores estão adotando esses modelos e modificando-os de maneiras novas e criativas. Esperamos que esta vitrine possa inspirá-lo a ver o que é possível. (Para aprender sobre os avanços na inteligência artificial, consulte Os computadores serão capazes de imitar o cérebro humano?)
Estilo Neural
Você não pode melhorar suas habilidades de programação quando ninguém se importa com a qualidade do software.
Narrador Neural

O Narrador de histórias neural é um modelo que, quando recebe uma imagem, pode gerar uma história de romance sobre a imagem. É um brinquedo divertido e, no entanto, você pode imaginar o futuro e ver a direção em que todos esses modelos de inteligência artificial estão se movendo.

A função acima é a operação de "mudança de estilo" que permite ao modelo transferir legendas de imagem padrão para o estilo de histórias de romances. A mudança de estilo foi inspirada em "Um algoritmo neural do estilo artístico".
Dados
Existem duas fontes principais de dados usadas neste modelo. MSCOCO é um conjunto de dados da Microsoft que contém cerca de 300.000 imagens, e cada imagem contém cinco legendas. O MSCOCO é o único dado supervisionado que está sendo usado, o que significa que é o único dado no qual os seres humanos tiveram que entrar e escrever explicitamente legendas para cada imagem.
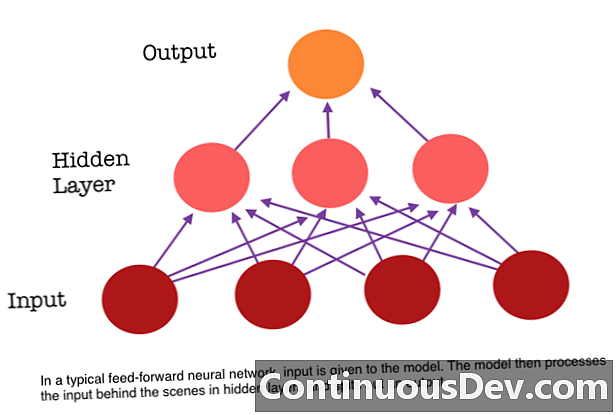
Uma das principais limitações de uma rede neural feed-forward é que ela não possui memória. Cada previsão é independente dos cálculos anteriores, como se fosse a primeira e única previsão que a rede já fez. Porém, para muitas tarefas, como traduzir uma sentença ou parágrafo, as entradas devem consistir em dados seqüenciais e relacionados ao mesmo tempo. Por exemplo, seria difícil entender uma única palavra em uma frase sem o engano fornecido pelas palavras ao redor.
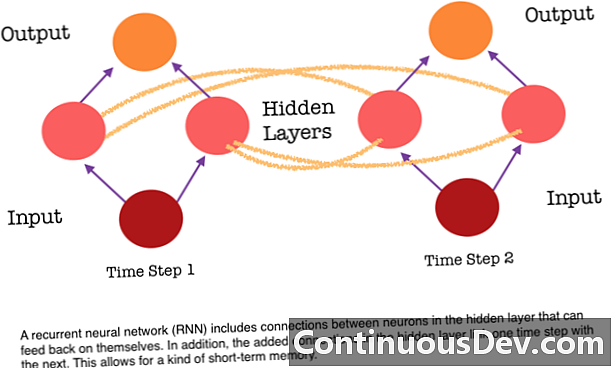
RNNs são diferentes porque adicionam outro conjunto de conexões entre os neurônios. Esses links permitem que as ativações dos neurônios em uma camada oculta retornem a si mesmas no próximo passo na sequência. Em outras palavras, a cada etapa, uma camada oculta recebe a ativação da camada abaixo dela e também da etapa anterior na sequência. Essa estrutura essencialmente fornece memória recorrente de redes neurais. Portanto, para a tarefa de detecção de objetos, uma RNN pode recorrer às classificações anteriores de cães para ajudar a determinar se a imagem atual é um cachorro.
Char-RNN TED
Essa estrutura flexível na camada oculta permite que os RNNs sejam muito bons para modelos de linguagem no nível de caracteres. Char RNN, originalmente criado por Andrej Karpathy, é um modelo que recebe um arquivo como entrada e treina um RNN para aprender a prever o próximo caractere em uma sequência. A RNN pode gerar caractere por caractere que se parecerá com os dados de treinamento originais. Uma demonstração foi treinada usando transcrições de várias palestras do TED. Alimente o modelo com uma ou várias palavras-chave e ele gerará uma passagem sobre as palavras-chave na voz / estilo de uma conversa TED.
Conclusão
Esses modelos mostram novas descobertas em inteligência de máquina que se tornaram possíveis devido ao aprendizado profundo. O aprendizado profundo mostra que podemos resolver problemas que nunca poderíamos resolver antes, e ainda não atingimos esse platô. Espere ver muitas coisas mais emocionantes, como carros sem motorista, nos próximos dois anos, como resultado de uma profunda inovação de aprendizado.